- December 8, 2024
- by Admin
- Web Scraping
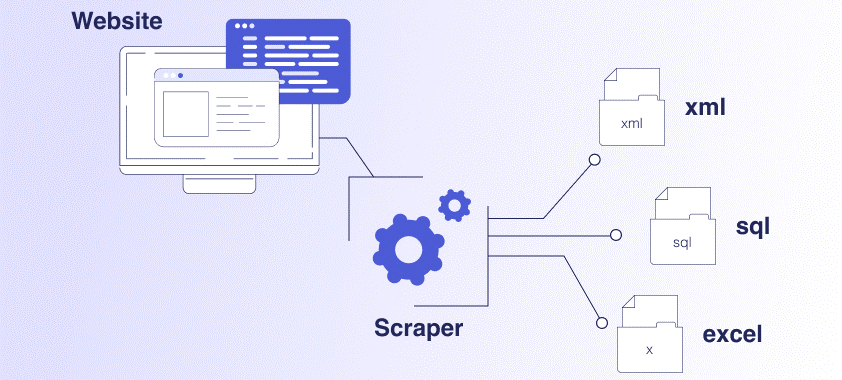
Web scraping is an approach that utilizes software intended for the extraction of information from a range of websites. These applications, referred to as web scrapers, facilitate the automation of the scraping process, enabling users to avoid the cumbersome task of manually retrieving data from each individual site.
Web scraping utilizes a combination of crawlers and scrapers to collect the necessary data. The web crawler explores the target websites and indexes their content, while web scrapers efficiently extract the information you require. You can specify the desired file format for the results and choose the storage location for the data that the web scraper will save.
What are the key differences between web crawling and web scraping?
Web scraping process
The initial phase of web scraping involves utilizing a web crawler to establish a connection with the target website that houses the required data. The complexity of this process can vary significantly based on the measures the website employs to safeguard its data from being scraped.
- At this juncture, it may be necessary to employ a proxy service to provide a distinct public IP address with specific attributes, aiding in circumventing the website’s bot-detection protocols.
- Should the target website feature dynamic content that is heavily dependent on JavaScript execution, it may also be essential to utilize a scriptable web browser. This type of browser possesses all the functionalities of a conventional web browser while allowing scripts to engage with its features.
- Additionally, it may be required to modify various fingerprints, such as TCP fingerprints, TLS fingerprints, or web browser fingerprint randomizers, to ensure that the web scraping client appears unique and consistent, thereby reducing its detectability when accessing websites.
After establishing a connection to the designated website, the crawler will download the complete content of the web page, which is formatted in HTML. This format is designed for efficient machine processing rather than for human interpretation. Web scrapers employ various techniques and tools to extract the precise information desired from the HTML content.
- Numerous libraries are available for this purpose, utilizing different methodologies and programming languages, including XPath, CSS selectors, and regular expressions (Regex).
- By leveraging these libraries and techniques, web scrapers can systematically traverse the HTML structure, focus on specific elements, and retrieve the pertinent data fields or content.
In practical scenarios, data scraping should not be performed solely for its own benefit. It is crucial to organize the data in a way that supports your business goals. After extracting data from HTML content, you may choose to apply several standard data engineering techniques to ensure that your information is both accurate and suitably formatted. These techniques include:
– Data cleaning: Remove irrelevant or incorrect entries.
– Data validation: Verify the accuracy of the data.
– Data correction: Amend any identified errors where possible.
– Data enrichment: Combine data from multiple sources.
– Data formatting: Modify the data structure to meet your business and storage needs.
– Data storage: Store your data in your preferred format.
If you are ready to start scraping a live website, we have published a detailed step-by-step guide on web scraping using Python. This guide is tailored for beginners, although some prior knowledge of Python will be advantageous.
What is web scraping used for?
Web scraping offers an extensive range of applications. A significant number of companies utilize bulk data to shape their strategies, and certain organizations even scrape data with the intent of repackaging and marketing it.
A company specializing in SEO tools may extract data from search engine results pages (SERPs) to determine the ranking positions of various websites for specific keywords. This information can subsequently be organized and sold to businesses seeking to enhance their search engine visibility.
Some of the most common web scraping use cases are:
- Ecommerce price tracking
- Search engine optimization (SEO)
- Market research
- Lead generation
- Social media marketing
- Brand monitoring
Web scraping examples
Scraping ecommerce data
Consider the scenario where you operate an online sneaker store. Utilizing web scraping techniques can enable you to track the pricing strategies of your competitors, ensuring that your prices remain competitive.
One can either construct or purchase a web scraping tool designed to automatically monitor the prices of similar sneakers on various online platforms. This tool visits those websites, extracts the pricing details, and sends them back to you. You can then analyse the collected data to determine if your pricing requires adjustment in accordance with market averages.
Imagine that you extract data from three well-known sneaker websites on a daily basis. Your web scraper gathers the prices of the specific sneaker models available for sale. After a week of monitoring, you observe that a competitor is consistently offering a certain model at a reduced price. With this insight, you have the option to either align your pricing with theirs or modify your marketing approach.
In this scenario, web scraping serves as a valuable tool for maintaining competitiveness by delivering up-to-date information regarding the pricing of comparable products. It enables you to grasp the competitive landscape effectively, without the necessity of dedicating significant time to manually review each website.
Web scraping API for ecommerce
Web scraping for search engine optimization (SEO)
A web scraper can be employed on search engines in the same manner as it is utilized on other websites. Search engines contain numerous fields suitable for scraping; for instance, one could extract all the meta titles from a search engine results page (SERP) or gather the URLs of the highest-ranking results. Additionally, it is possible to scrape search engines for data related to their image results.
Envision a situation in which you are responsible for the SEO of a travel website that specializes in vacation packages. Your objective is to determine which websites are achieving high rankings on Google for travel-related keywords. Gathering this information will allow you to gain insights into your competitors’ tactics and discover methods to elevate the visibility of your travel website to attract potential customers.
Employing a web scraping tool for Google Search facilitates the automatic acquisition of data regarding the websites that rank prominently for crucial travel-related keywords. By analysing these top-ranking sites, you can uncover effective tactics that can be mirrored on your own website.
As an illustration, should you notice that some competitors are thriving in specific keyword categories, it would be prudent to revise your content strategy to more accurately focus on those keywords. Furthermore, you might optimize meta tags, bolster backlink profiles, or adjust various components of your SEO strategy based on the information derived from competitor rankings.