
- December 5, 2024
- by Admin
- Web Scraping
In the present data-driven age, the practice of Web Scraping with AWS Lambda has gained significant importance for businesses, researchers, and developers focused on extracting valuable insights from websites. The rapid evolution of e-commerce, combined with the necessity for real-time data gathering and online research, has made scalable web scraping processes increasingly vital. Conventional methods of scraping data can often be resource-intensive and challenging to scale, especially when regular extraction from various sites is required. This is where cloud computing solutions like Real-Time Web Scraping with AWS Lambda come into play.
What is AWS Lambda?
AWS Lambda, a service provided by Amazon Web Services, offers serverless computing capabilities that enable code execution without the necessity of server management. This service automatically adjusts the performance of your applications by running code in reaction to events and accommodates various programming languages, including Python, JavaScript (Node.js), and Java. The serverless design of AWS Lambda ensures that you are charged only for the compute time consumed, which can greatly lower expenses, especially for tasks such as web scraping that demand the handling of multiple requests at scale.
Utilizing the AWS Lambda Ecommerce Price Tracker allows for the creation of scalable applications that seamlessly adjust to load fluctuations, scaling up or down according to demand without requiring server or infrastructure management. Consequently, AWS Lambda serves as an excellent solution for scalable web scraping projects.
The Advantages of Utilizing AWS Lambda for Web Scraping
Before diving into the implementation details, it’s essential to understand why AWS Lambda is an excellent choice for scalable web scraping:
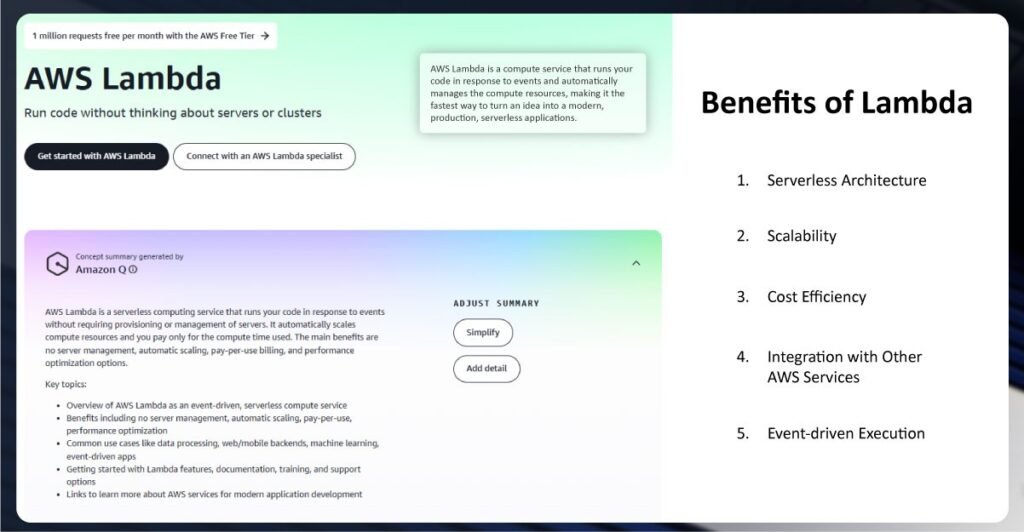
- Serverless Architecture: Utilizing Web Scraping APIs with AWS Lambda removes the necessity of infrastructure management. You simply develop the scraping code and upload it to Lambda, while AWS takes care of resource management and scaling in response to incoming requests.
- Scalability: AWS Lambda facilitates data collection by automatically scaling to accommodate numerous concurrent scraping tasks and reducing capacity when demand wanes. Whether the task involves scraping a handful of pages or thousands, Lambda adapts accordingly.
- Cost Efficiency: The model for Ecommerce Data Scraping with AWS Lambda operates on a pay-per-use basis, ensuring that you are charged solely for the compute time utilized. This eliminates ongoing expenses associated with idle servers, presenting a considerable benefit for scalable scraping initiatives.
- Integration with Other AWS Services: Lambda offers seamless integration with various AWS services, including Amazon S3 for data storage, AWS DynamoDB for database results, and AWS CloudWatch for monitoring and logging purposes. This integration fosters a comprehensive ecosystem for AWS Lambda in Ecommerce Inventory Tracking applications.
- Event-driven Execution: Lambda can be activated by a range of events, such as HTTP requests through API Gateway, modifications in data within Amazon S3, and scheduled tasks via Amazon CloudWatch Events. This capability makes it ideal for automating scraping operations.